Context & Motivation
Modern world-model agents like NEWT (Hansen et al., 2025) achieve strong reward on continuous-control benchmarks, but they're trained with no notion of safety — a deployed racing car that maximizes lap reward will happily collide with hazards if reward dominates. The goal of this project was to take a fixed, pretrained NEWT encoder and ask: given the same perceptual backbone, which safety paradigm produces the best reward-under-constraint? I evaluated three approaches on the SafetyRacecarFormulaOne1-v0 environment from Safety Gymnasium, controlling for encoder, RL backbone (TD3), and seed.
System Architecture
All three agents share a frozen NEWT encoder feeding a TD3 actor-critic. The only thing that varies is the safety layer stacked on top.
Three Safety Paradigms
1. Vanilla TD3 (Unconstrained Baseline)
A standard TD3 agent on the NEWT latent. No cost signal enters the optimization — the agent is only told to maximize episodic return. This establishes the reward ceiling and the unsafe lower bound for the comparison.
2. Lagrangian Safe-RL (Warm-Started from CarRun Expert)
A two-stage pipeline. First, a Lagrangian TD3 agent is trained on the simpler SafetyCarRun-v0 environment to produce a cost-aware policy prior. The weights — including a learned Lagrange multiplier λ — are then transferred and continued on FormulaOne:
λ is updated by gradient ascent on the constraint violation, automatically tightening when the agent exceeds the per-step cost budget δ = 0.1. Warm-starting from CarRun avoids the cold-start problem where λ explodes before the actor has any useful behavior.
3. Online Control Barrier Function Shield
Instead of penalizing cost in the reward, the CBF approach filters unsafe actions at runtime. A neural CBF h(z) is trained over the NEWT latent: h > 0 means safe, h < 0 triggers a brake override. The CBF is warm-started supervised on PPOLag demonstration transitions, then continuously updated online from the replay buffer:
a = (h > 0) ? πTD3(z) : brake
Lcls = weighted hinge(−h(z) · label), unsafe × 10
Lcbf = mean clamp(−(h(z') − (1−γ)·h(z)), 0)
Lcbf enforces forward invariance — once safe, the system should remain safe. γ = 0.2 controls how fast h is allowed to decrease along trajectories.
Quantitative Results
All agents were evaluated at matched timesteps (30k) on the same environment seed. The Safety-Constrained Return reports the best eval return achieved while staying under a cost budget of 25 steps/episode.
| Agent | Peak Return | Mean Cost | CVR | SC-Return |
|---|---|---|---|---|
| Vanilla TD3 | 2.38 | 53 – 371 | 12.1% | ~0.00 |
| Lagrangian Safe-RL | 0.26 | 1.3 | 4.5% | 0.214 |
| CBF Shielded | 0.86 | 11.6 | 2.8% | 0.856 |
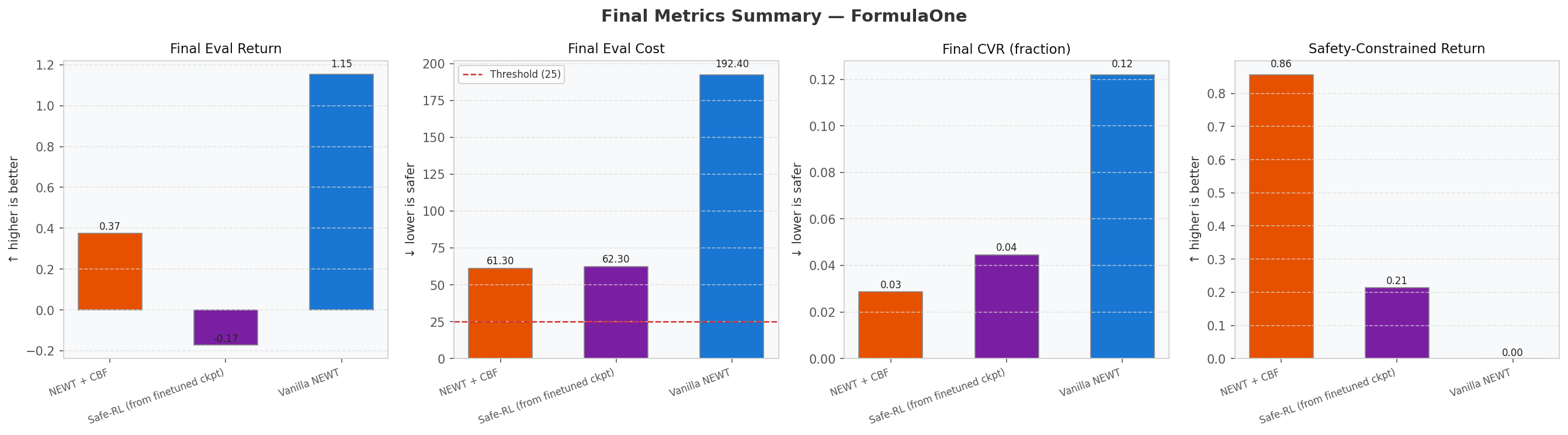
Final-step metric comparison
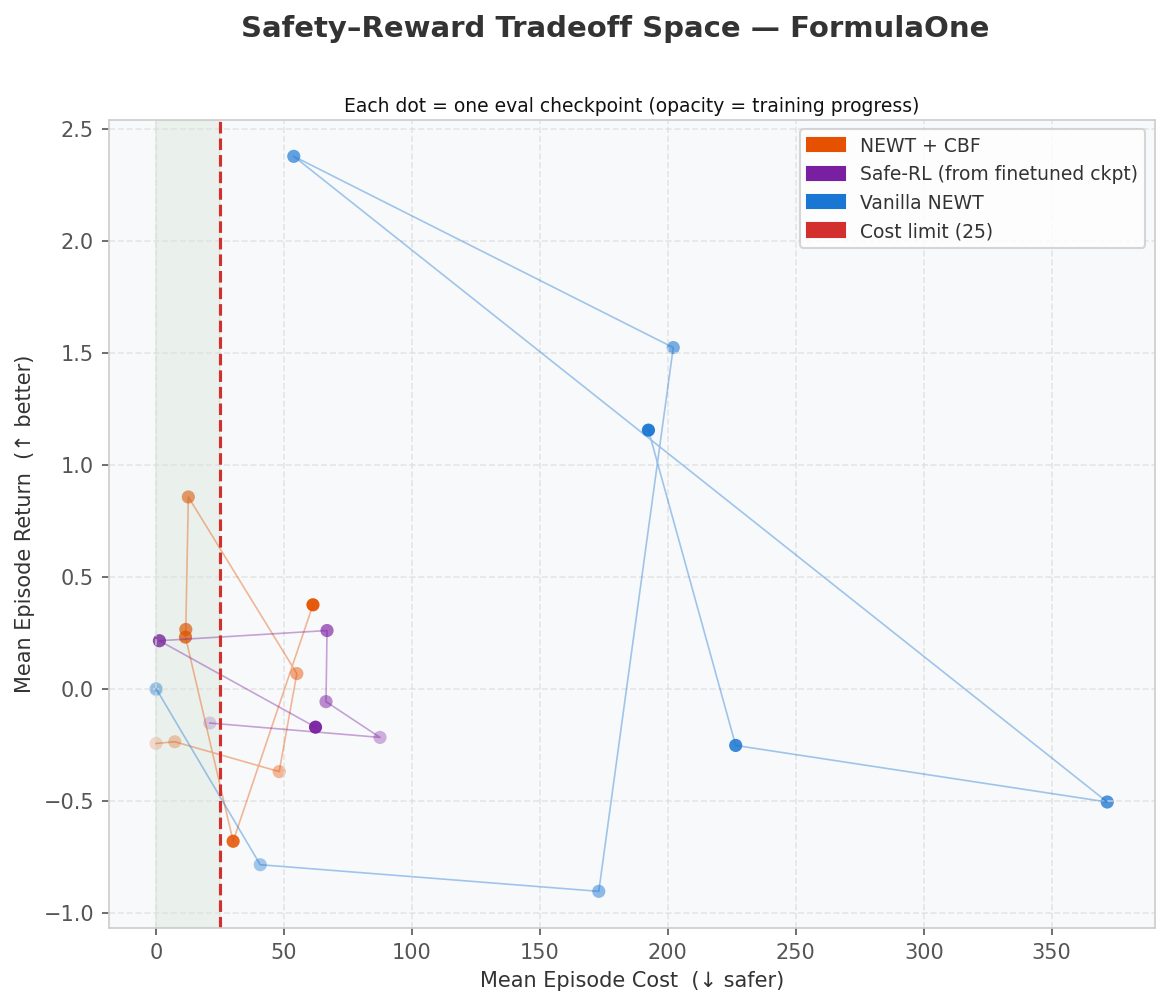
Reward vs. cost Pareto frontier
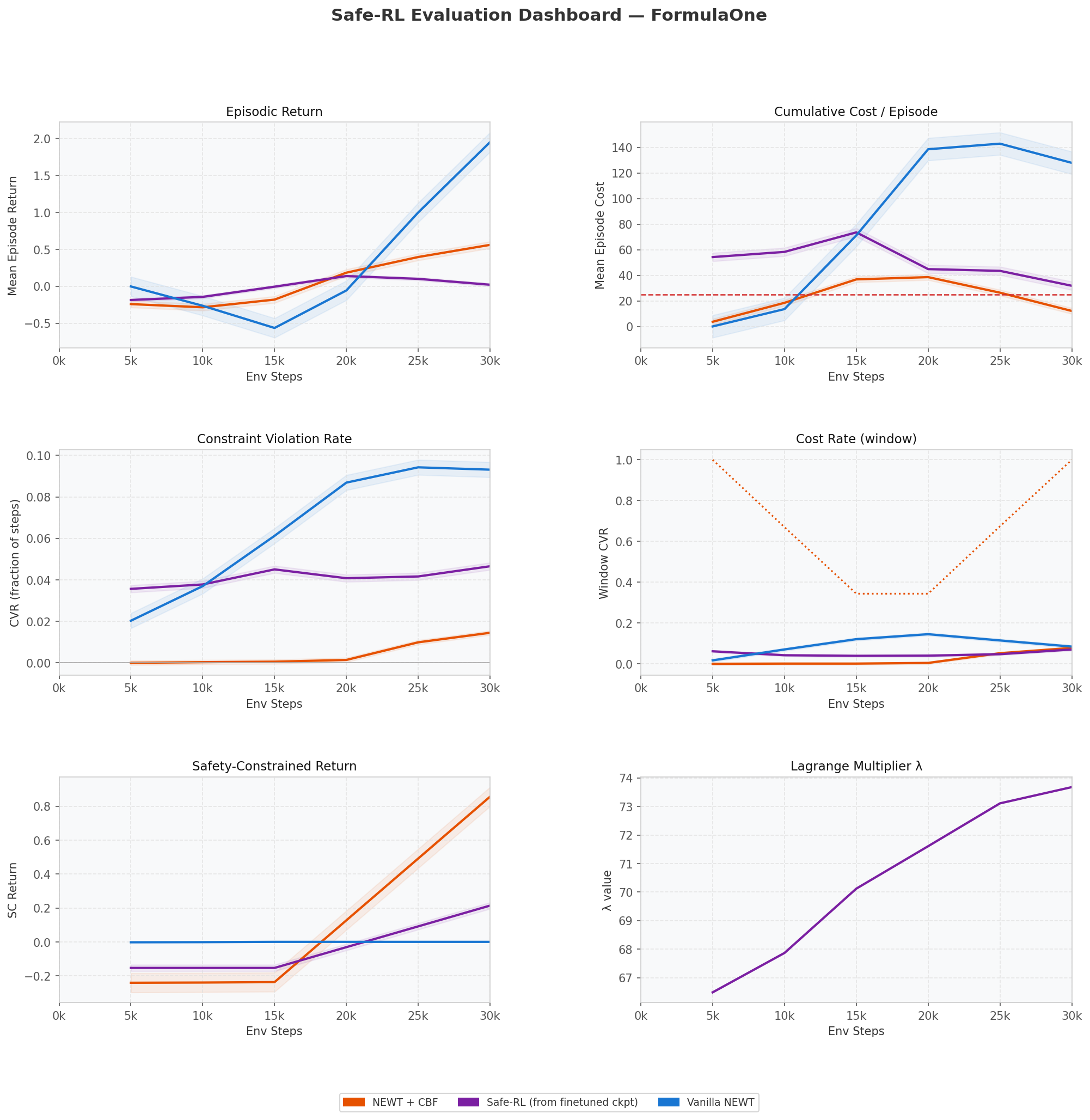
Per-checkpoint eval dashboard: return, cost, CVR, cost rate, SC-return, and λ trajectory
Qualitative Behavior
The recordings below are each agent's best evaluation episode. Note the difference in driving style — the vanilla agent cuts corners aggressively, the Lagrangian agent crawls along the safe centerline, and the CBF agent balances the two by braking only when the learned barrier predicts an upcoming hazard.
Vanilla TD3
Lagrangian Safe-RL
CBF Shielded
Training Dynamics
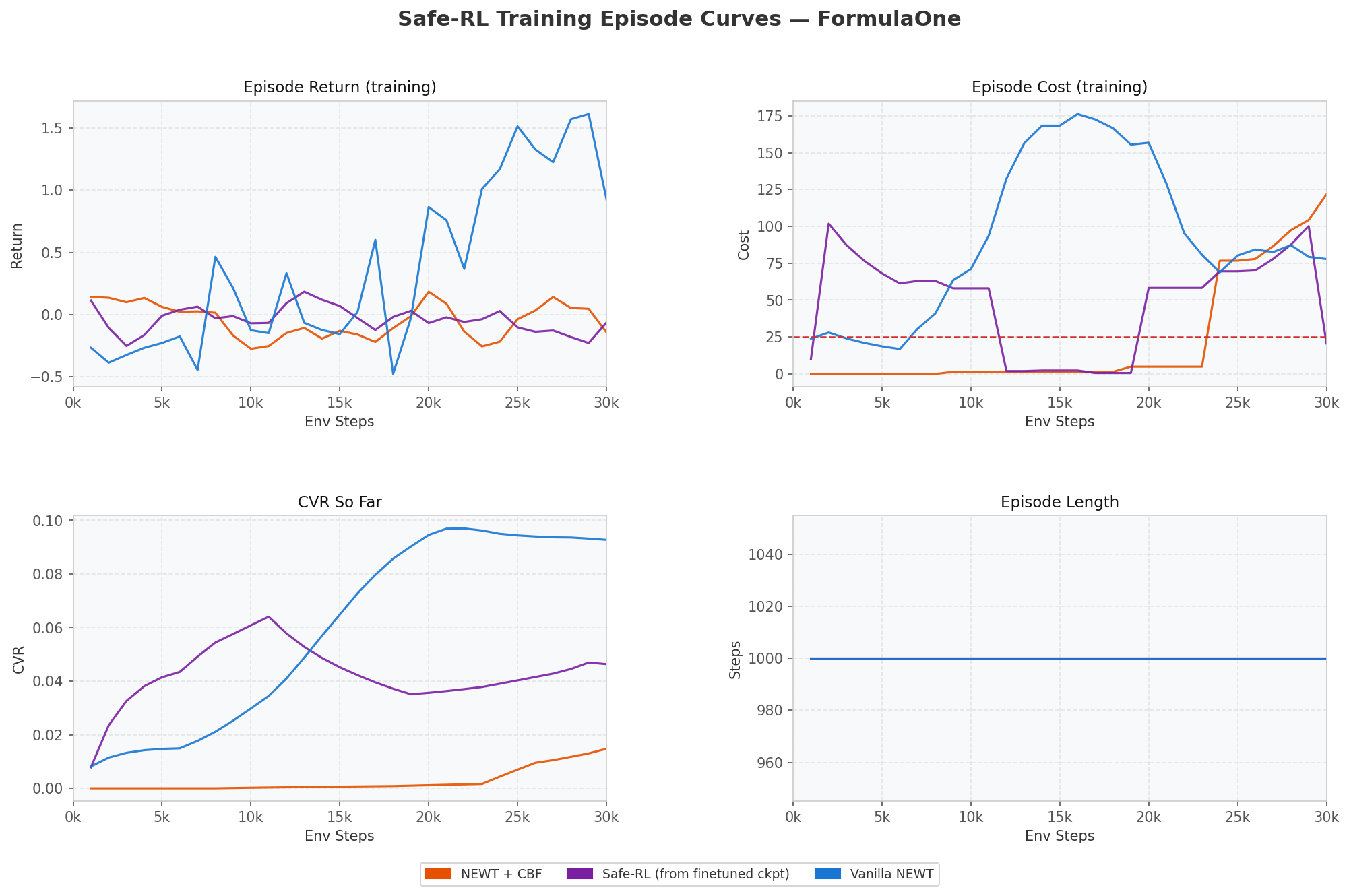
The Lagrangian λ climbs monotonically from 65 → 75 over 30k steps as the agent repeatedly exceeds its cost budget — the constraint genuinely binds rather than acting as a soft regularizer. The CBF intervention rate is the inverse story: it starts at 100% (the untrained barrier rejects everything), drops to ~1% during the supervised warm-start as the agent learns to act on its own, and re-rises to ~100% once the online updates kick in and the barrier sharpens on FormulaOne-specific failure modes.
Engineering Lessons
- Warm-starting matters more than the algorithm. A CBF trained from scratch on FormulaOne takes >100k steps to do anything useful; warm-started from 50k PPOLag demo transitions, it's usable in 5k steps. Same story for Lagrangian — the CarRun prior is doing most of the work.
- Frozen-encoder transfer worked. The NEWT encoder was pretrained on a different task family, but its latents proved discriminative enough that a small (3-layer MLP) CBF head learned a useful safety classifier on top — no fine-tuning required.
- "Safety-Constrained Return" is the right headline metric. Looking only at reward picks vanilla TD3 every time; looking only at cost picks the agent that never moves. SC-return forces the comparison to live on the actual Pareto frontier.
- CBF beats Lagrangian on this task — but the win is environment-specific. Lagrangian is harder to tune but provides asymptotic constraint guarantees the CBF doesn't.